Visualizing: What We Don’t Know (Pt. II)
If you haven’t already, take a look at Pt. 1 of “What We Don’t Know” to learn about other obstacles in the Veterans History Project archive.
The Incredible Transcribing Robot!
The CCSU Veterans History Project features over 700 oral histories, which are all viewable on YouTube. And one of the many benefits of that platform is YouTube’s capacity to auto-generate transcripts.
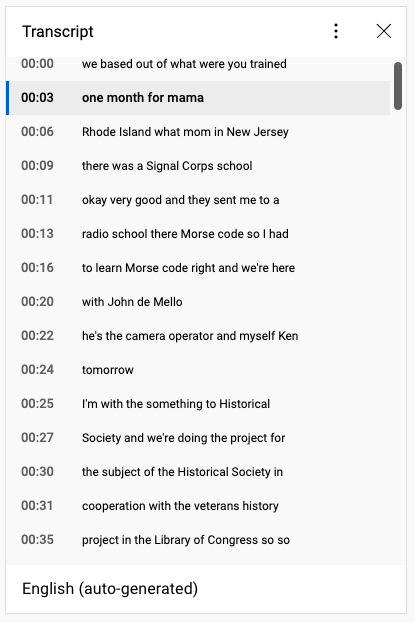
Transcripts are immensely useful, not just because they offer subtitles for viewers who may have a hard time hearing or understanding the interview.
Referencing the time-coded transcript of an interview allows a viewer to quickly identify and navigate to relevant sections. Without it, the only way through is the old fashioned one: watching from start to finish.
If you’ve been reading some of the other Visualizing posts, you know that we love reaching for our digital humanities toolkit. And auto-generated YouTube transcripts offer a perfect opportunity to put on our hardhats and start building something:

What if we could collect ALL 700+ YouTube transcripts in one spot? Then we could:
- Analyze the contents of ALL interviews at once
- AND navigate to specific interviews based on their contents
Right now, the Veterans History Project Archive is searchable only by “tags.” These tags are the written answers that accompany each entry: Name, Branch, War, Conflict, Gender, etc.
As we saw in Pt. 1, these “tags” have some shortcomings.
Now, imagine a new set of searchable “tags” consisting of every word spoken in every interview in the archive!
Sound too good to be true? That’s because it is.
The Just Ok Transcribing Robot!
Unfortunately, YouTube’s speech recognition technology has problems.
Much as we appreciate free and fast transcription services, variables such as audio quality, accents, and unusual words/phrases pose a problem. This neat little transcription robot occasionally even misidentifies the language being spoken, leading to some Spanish transcriptions of English words.
Mind you, we’re not talking about a translation. The transcription bot is trying to hear Spanish words in English speech as in this example:

Other problems pop up with unrecognized words or names. “Fort Monmouth,” a base in Rhode Island, was one such example:

Until we can fund a human stenographer to go through and create verified transcripts of every video, these robot-generated transcripts are the best resource we have. And we can’t let the perfect be the enemy of the good.
So how do we collect all these transcripts in one place?
The Incredible Scraping Robot!
Once again, we reach into our trusty digital humanities toolkit:
Python is a free programming language, capable of automating computer processes.
Selenium Webdriver is a free interface (actually, a collection of interfaces, but let’s not split hairs) for accessing web based applications.
By combining Python and Selenium, we can create a program that can interact with a given web page.
Collecting transcripts from YouTube is fairly easy by hand:
- Open a YouTube video webpage.
- Click the “More Info” button.
- Click the “View Transcript” button.
- Copy the transcript.
- Paste the transcript into a document on your computer.
With Python, we can write instructions for Selenium to perform these 5 steps. And not just for one video, but over and over again for all 700+ interviews in the archive.
After more than a few misfires we got just such a robot working. We call it:

Scrappy the Scraper
All we have to do is provide Scrappy with an excel spreadsheet listing every video’s URL (web address) along with the corresponding veterans name.
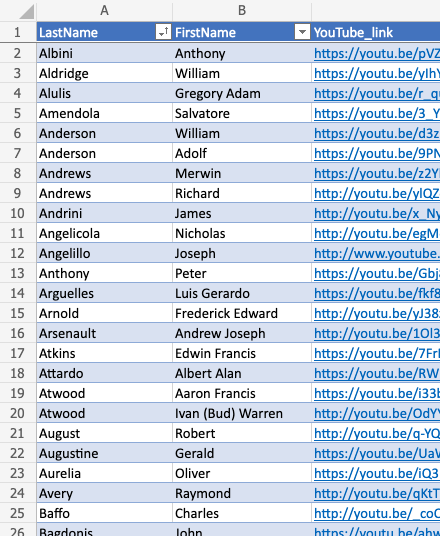
Get Scrappy running, and it tears through the list faster than any human could.
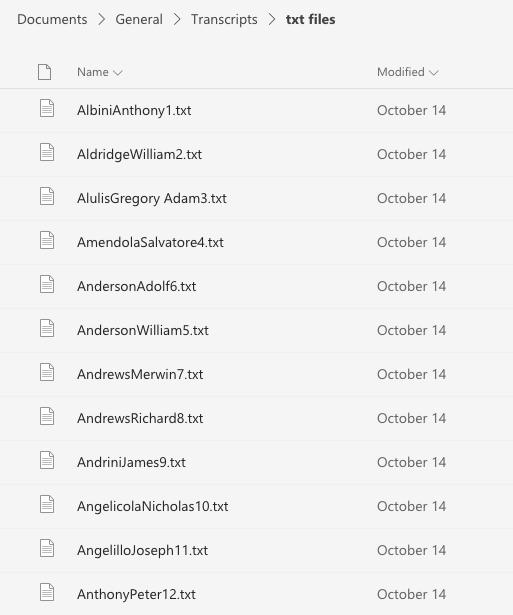
For each video, Scrappy creates a .txt and .csv file of the transcript. The former contains the raw words only, while the later preserves time-codes along with the transcription.
When Scrappy finishes, we have two neat new folders containing 700+ transcripts, each bearing the respective veterans name.
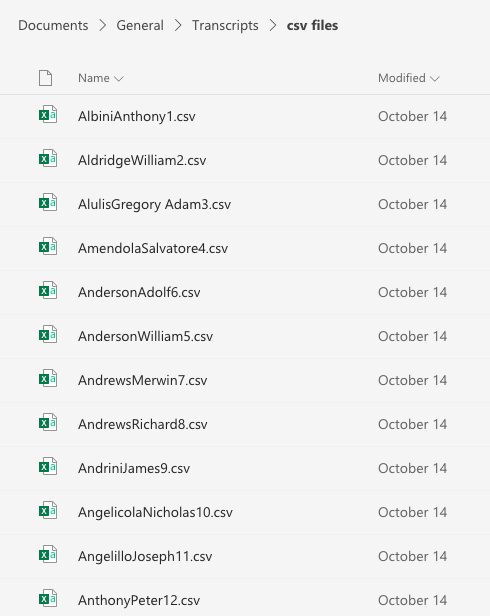
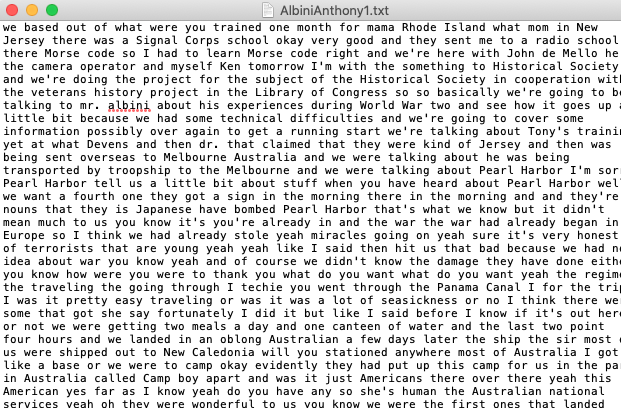
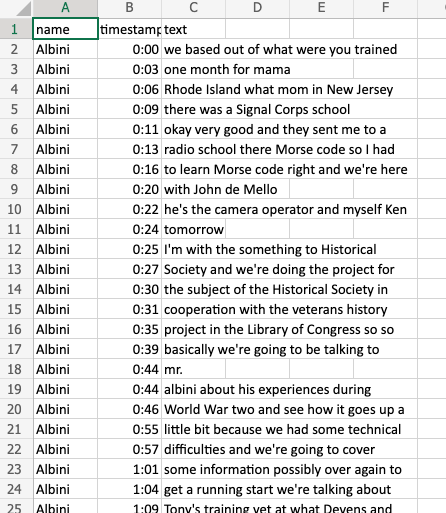
Analyzing Transcripts
With our collection of transcript files in hand, we can again turn to Voyant.org for textual analysis.
We’re already familiar with Voyant’s ability to create word clouds, but what about something more?
This time, we’ll try quantifying the usage of specific words to see how many interviews featured them, and how many times each word appeared overall. The results are easily fed into yet another free program, R:
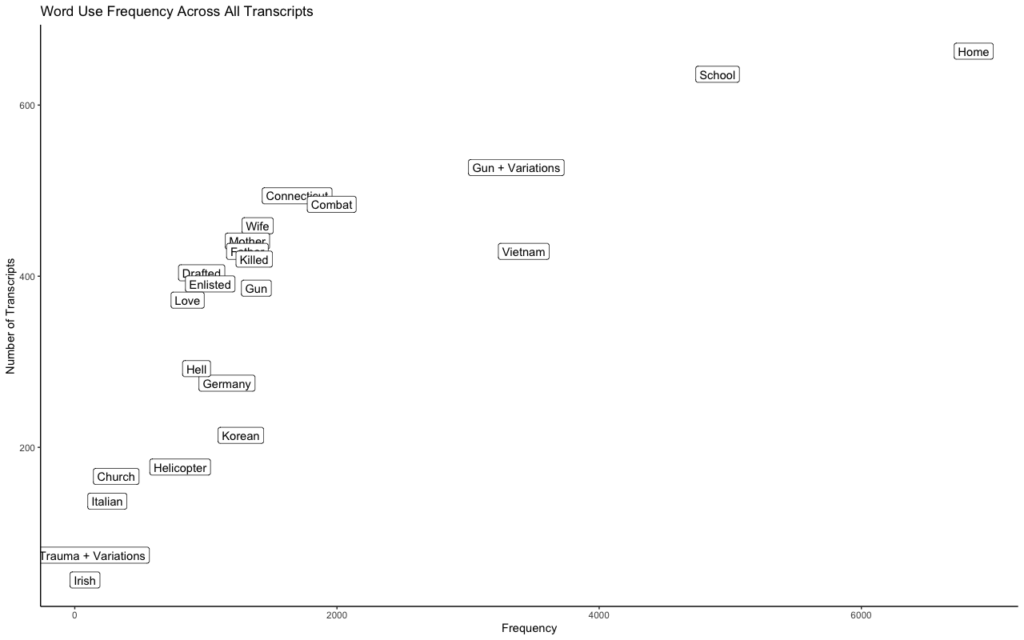
It’s immediately obvious that some terms occur more than others. But for each case we have to ask: Why?
What We Don’t Know
It’s easy to think that the frequency of a word correlates to its commonality or importance. For instance, maybe “home” appears because every soldier got homesick. Maybe “school” is frequently referenced because soldiers talked about places they’d rather be.
Some phrases, like “enlisted” appear because interviewers used them in their questions, and veterans often used the same word in their answers. Because the same questions were posed in every interview, some words registered frequently, but in reality just express the interests of the interviewer.
Unfortunately, similarly banal explanations are available for most words. Many veterans discussed their enlistment relative to their time in high school. But by age 18, most people have shared one common experience: “school.”
Our collection of transcripts remains useful (especially as a supplemental tool to our “tags”) but only when we are aware of its limitations.
For now, the next step is improving the transcripts we have: correcting the language, rewriting erroneous transcripts, and creating new transcripts for audio that the YouTube bot couldn’t understand.
These aren’t glamorous tasks, but each one promises to improve the archive by chipping away at what we don’t know.